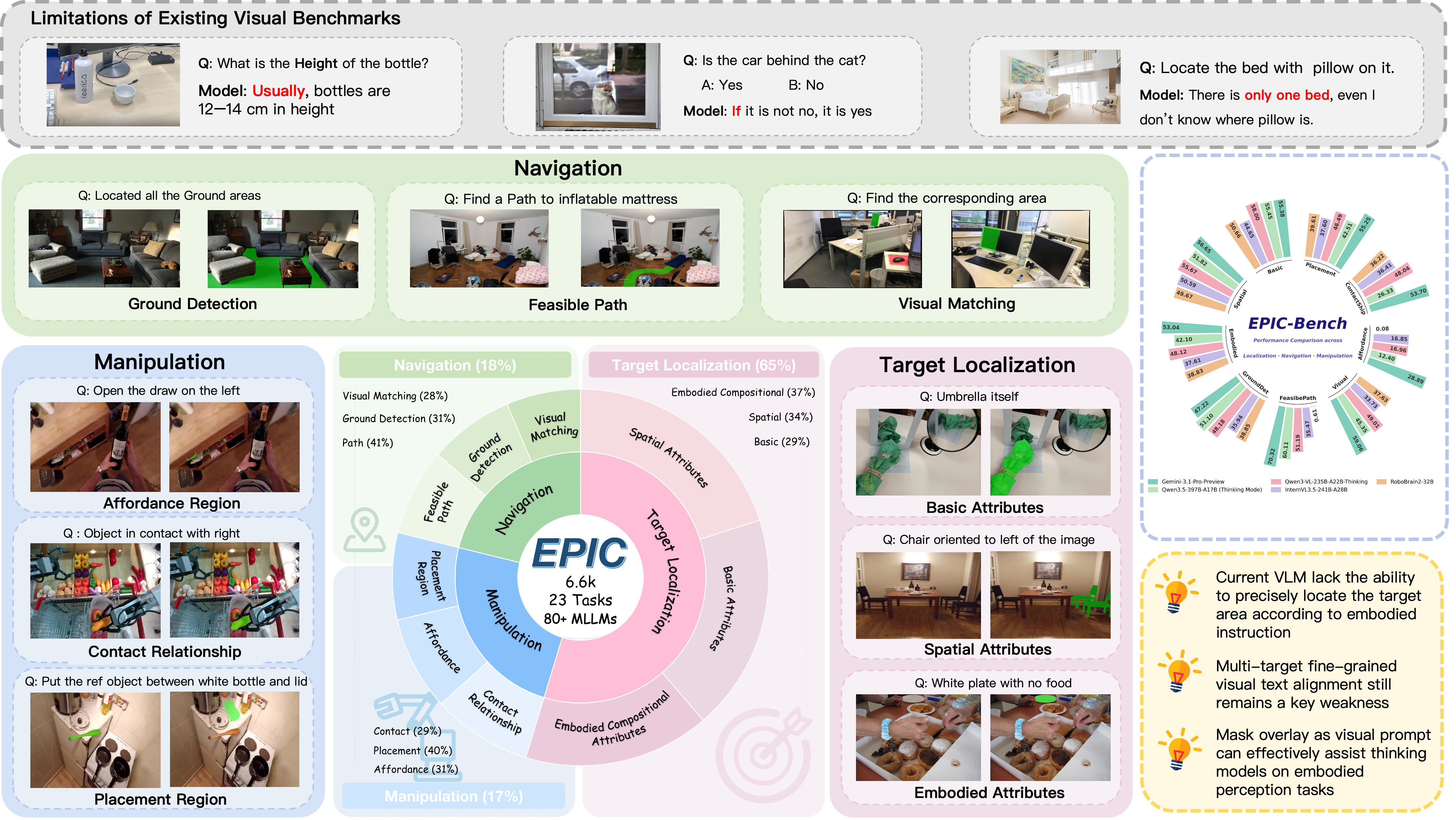
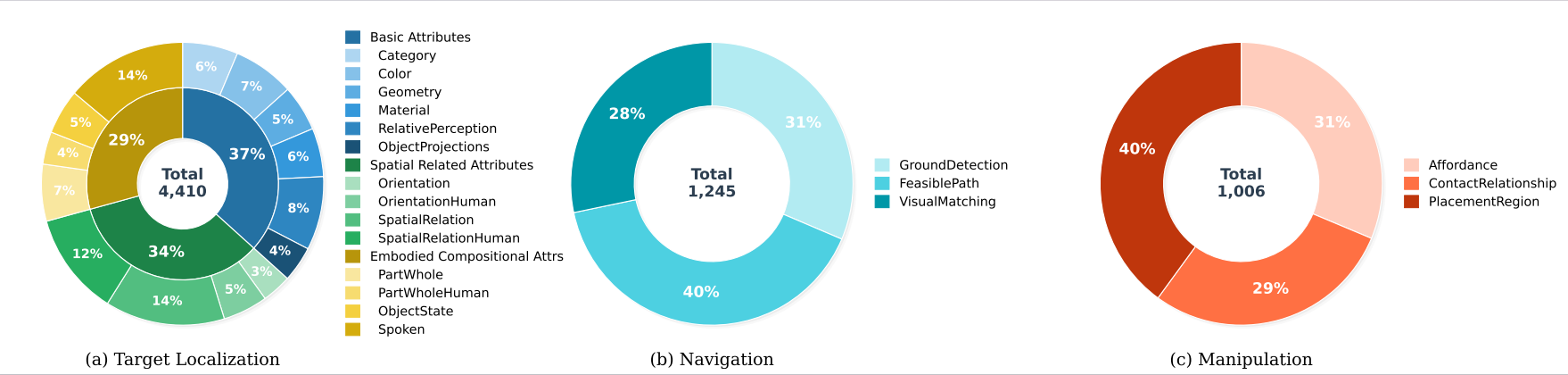
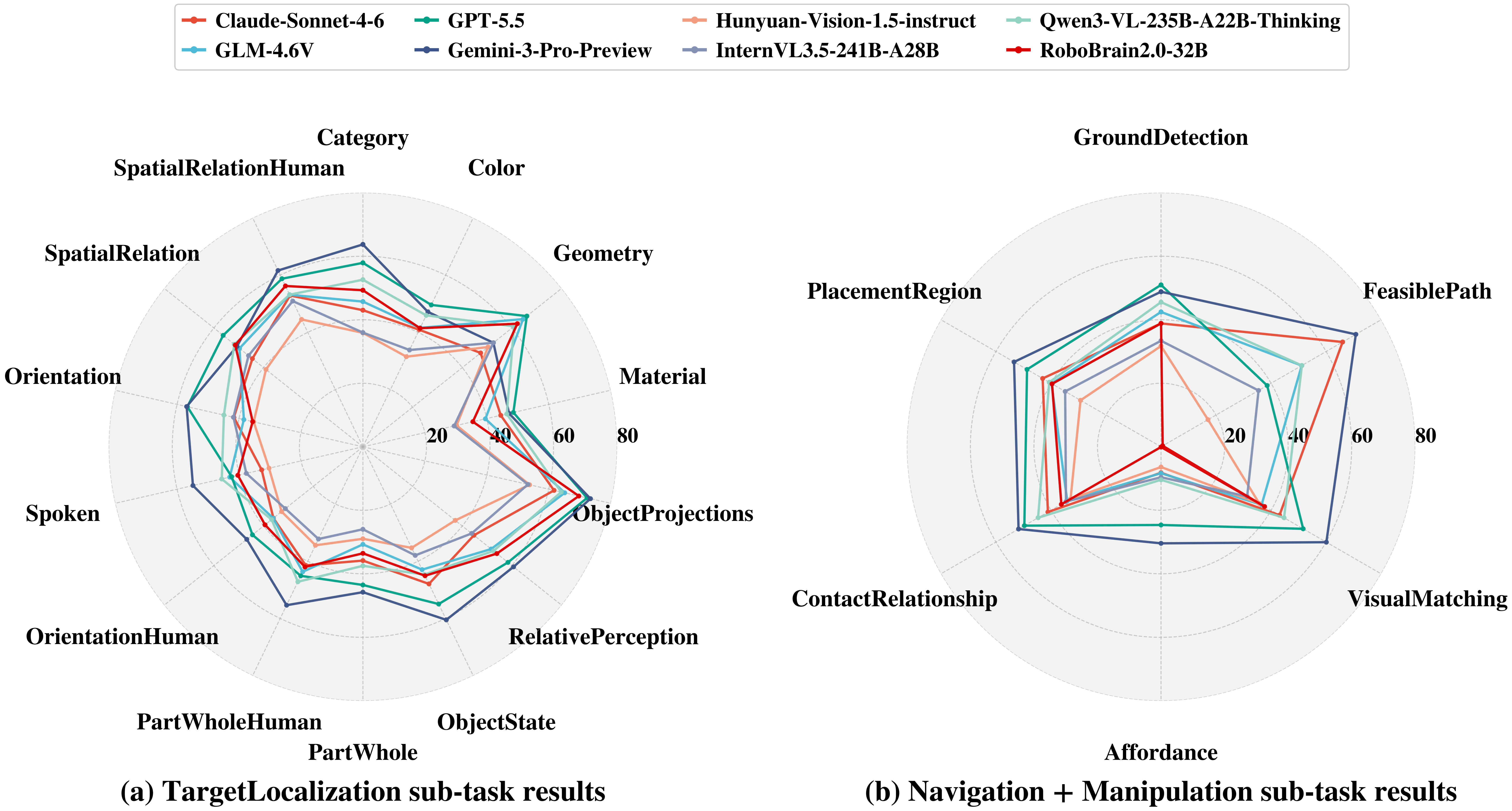
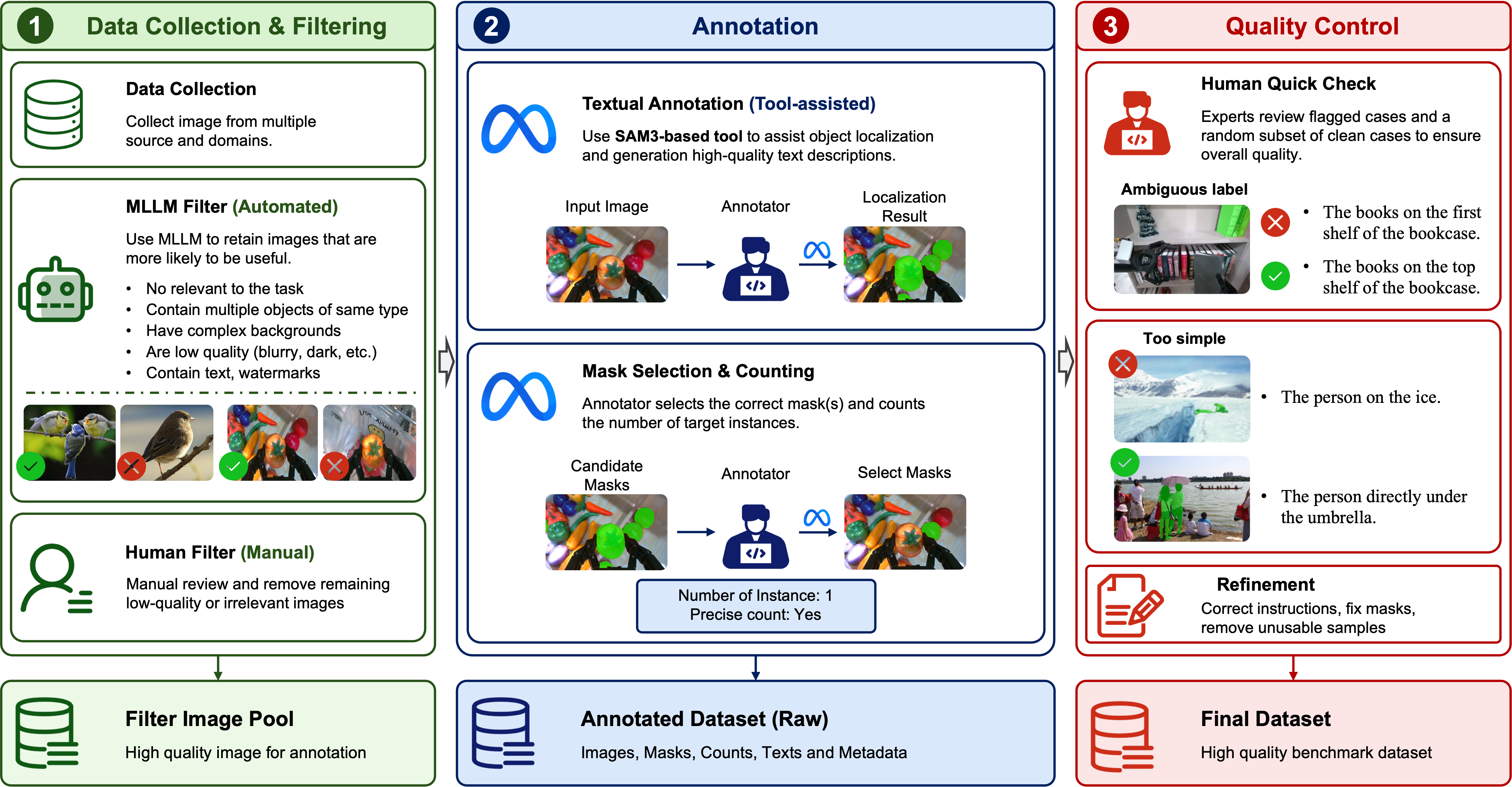
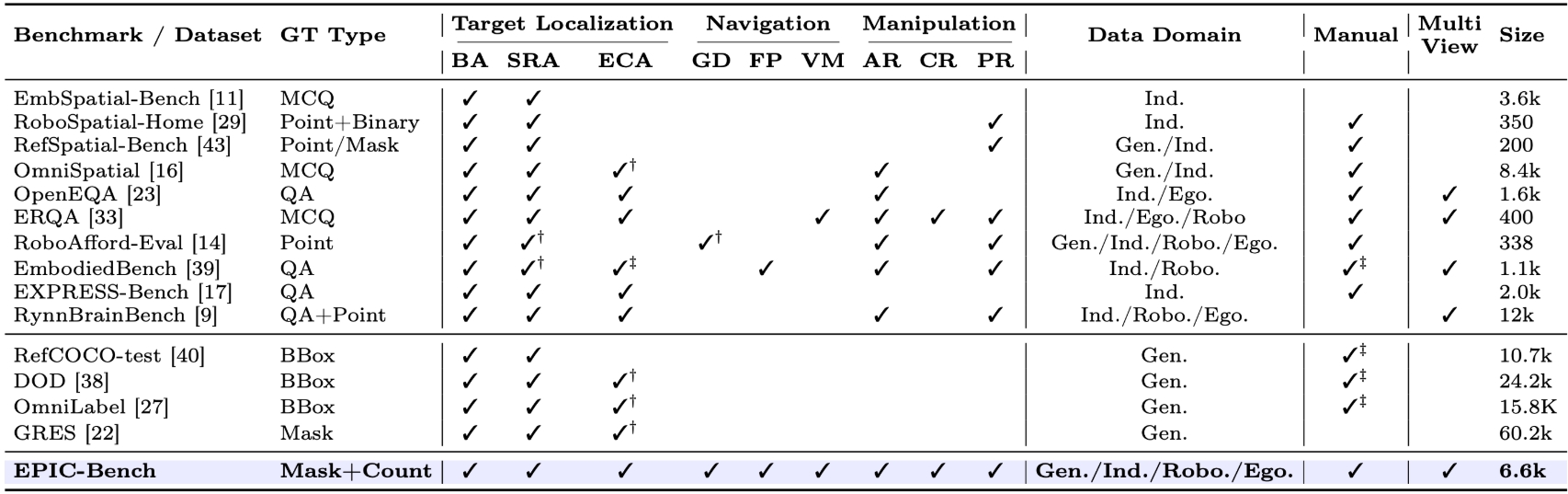
This work presents EPIC-Bench, Embodied PerceptIon BenChmark, a grounding benchmark designed to systematically evaluate the visual perceptual capabilities required for large vision-language models (VLMs) in embodied environments. We construct a dataset of 6.6k meticulously annotated (Image, Text, Mask) tuples, to answer the question: Can VLMs perceive the embodied real-world? EPIC-Bench is characterized by three key design principles. First, it encourages genuine visually grounded perception without exploiting linguistic priors. Second, it comprises 23 fine-grained tasks spanning the embodied interaction pipeline from Target Localization to Navigation and Manipulation. Third, its fine-grained taxonomy supports diagnostic analysis of embodied visual perception. Comprehensive experiments show that VLMs still struggle to align visual–text information for downstream physical interactions, especially in affordance region detection, where the target is only part of an object.
@misc{shan2026epicbenchperceptioncentricbenchmarkfinegrained,
title={EPIC-Bench: A Perception-Centric Benchmark for Fine-Grained Embodied Visual Grounding in Vision-Language Models},
author={Haozhe Shan and Xiancong Ren and Han Dong and Haoyuan Shi and Yingji Zhang and Jiayu Hu and Yi Zhang and Yong Dai and Bin Shen and Lizhen Qu and Zenglin Xu and Xiaozhu Ju},
year={2026},
eprint={2605.17070},
archivePrefix={arXiv},
primaryClass={cs.CV},
url={https://arxiv.org/abs/2605.17070},
}


 ModelScope
ModelScope